背景
好久没写文章了, 自从换工作以后整天就忙着熟悉新公司的项目了。 趁着这两天有时间我就继续更新一下大数据测试系列。 上一次我们聊过流计算场景一般的测试方法,而流计算是在线业务。 那今天我们聊聊离线业务的场景。 不知道大家有没有接触过大数据平台产品, 这类产品以 TO B 公司居多, 当然也有一些大厂内部也会有大数据平台去支撑业务线, 比如阿里的好像叫 odps 吧(有点忘了), 腾讯也有 tbds 这样的大数据产品。 或者一些 AI 平台也有着大数据平台的特性。 它们的特点是产品属于平台类的, 没有自己的业务, 或者说他的业务就是提供算力去支撑客户的业务。 也就是大数据平台类的产品提供的是一些原始算力, 用户需要调用这些算力来满足他们的业务。 这就跟互联网不太一样了, 接触过大数据的同学比较熟悉的应该还是在业务层的数据处理逻辑, 比如测试一些研发提供的 ETL 程序, 或者数据组的同学提交的一些 hive sql。 这些都是带着强烈的业务属性的,属于业务层的东西。 而大数据平台的产品并没有这些属性, 可以理解为它属于中台层。
场景举例
上面说的过于抽象,我们用个例子来说明一下。 一般企业在发展到一定程度,数据积累到一定量级都会发展出数仓(数据仓库)应用, 数仓一般用来做类似 BI 的业务帮助企业分析数据以做出决策, 我用知乎上一个仁兄举的例子来说, 比如需求会从最初非常粗放的:“昨天的收入是多少”、“上个月的 PV、UV 是多少”,逐渐演化到非常精细化和具体的用户的集群分析,特定用户在某种使用场景中,例如 “20~30 岁女性用户在过去五年的第一季度化妆品类商品的购买行为与公司进行的促销活动方案之间的关系”。这类非常具体,且能够对公司决策起到关键性作用的问题,基本很难从业务数据库从调取出来。 主要原因我觉得有 3 点:
业务数据库中的数据结构是为了完成交易而设计的,不是为了而查询和分析的便利设计的。
业务数据库大多是读写优化的,即又要读(查看商品信息),也要写(产生订单,完成支付)。因此对于大量数据的读(查询指标,一般是复杂的只读类型查询)是支持不足的。
我们需要大量的数据来进行分析, 但这些数据不都是存在关系型数据库中的, 数据源可能来自消息中间件也可能来自日志系统。 我们在分析的时候需要对接多种数据源
所以综上所述, 到了这个阶段的企业不会再用 mysql 这种关系型数据库来构建数据仓库了, 而是使用诸如 hive 这样的技术来构建数仓。 因为数仓的要求一般为:
数据结构为了分析和查询的便利;
只读优化的数据库,即不需要它写入速度多么快,只要做大量数据的复杂查询的速度足够快就行了。
一般的大数据平台都会提供数仓的能力。 而构建数仓的第一步就是如何从各种数据源中把业务数据导入到数仓中(这其中还需要清洗过滤数据, 多表拼接, 规范 schema 等 ETL 流程)。 所以很多大数据平台会提供从各种数据源中把数据导入到平台自身系统存储的功能。 并且这些导入功能要保证功能的前提下也要保证性能,一致性,高可用等等。
测试工具
好了, 上面说的都是背景, 是为了引出我们的测试需求而存在的。 现在我们知道了, 对于大数据平台类产品来说, 一般都得提供从非常多的数据源中导入数据的能力以应对客户的需求。 毕竟客户自己使用的数据存储花样层出。 那么对于测试来说, 如何能保证所有平台支持的数据源都是没有问题的是一个挑战。 这里面的难点有二:
数据源兼容性:每种数据源都有不同的版本和不同的配置。 比如 hdfs 有商业版本的也有开源版本的, 有开了 kerbos 安全认证的也有没开的。 需要部署安装各种版本的数据源进行测试。 当然今天的帖子里不针对这个详细展开了,我们主要讲下面一个。
数据兼容性: 我实在不太知道应该起什么名字了。 因为这一条里其实包含了功能,性能等各方面的东西, 暂且叫数据兼容性。 因为测试方法其实就在不同的数据源中构建不同的数据进行测试。 你要保证在每个数据源下不同格式,不同结构,不同量级的数据都是能保质保量的导入到产品中的。
专门针对上面第二点说,其实测试就是要保证所有数据源在导入的时候功能和性能都是合格的。 所以为了测试这种场景你就需要一个比较强大的造数工具, 可能有些同学会问干嘛不直接用线上数据。 当然如果有线上数据我也倾向于采集线上数据, 但是很多大数据平台其实都没有线上这个概念, 因为它们都是私有化部署在客户场地内的, 客户的数据是不会交给你的。当然不止这一个原因,我们有时候会碰到各种原因而无法使用线上数据。 所以我们在有些情况下,是需要这个造数工具的。 而这个造数工具有几个难点:
构建大数据: 造数工具的性能够不够? 如果有一个造 10 亿行,1000 列的数据的要求,能不能在短时间内把这些数据造出来。
多种数据源: 因为我们要测试所有的数据源,而每种数据源的造数方式那是不一样的。 要是每种数据源都写一个造数工具那成本还是非常高的。
多种数据格式,分布,类型和结构: 造数是个比较复杂的事, 除了每个字段的类型要控制, 还有文件的类型(txt,csv,parquet 等),还要控制两张表的关系(测试拼表场景),还要控制数据分区和分片(分布式文件数据源的场景)。 所以要怎么设计这个造数据工具能满足这些场景。
考虑到这 3 个难点, 所以我们在设计造数工具的时候采用了下面的方案
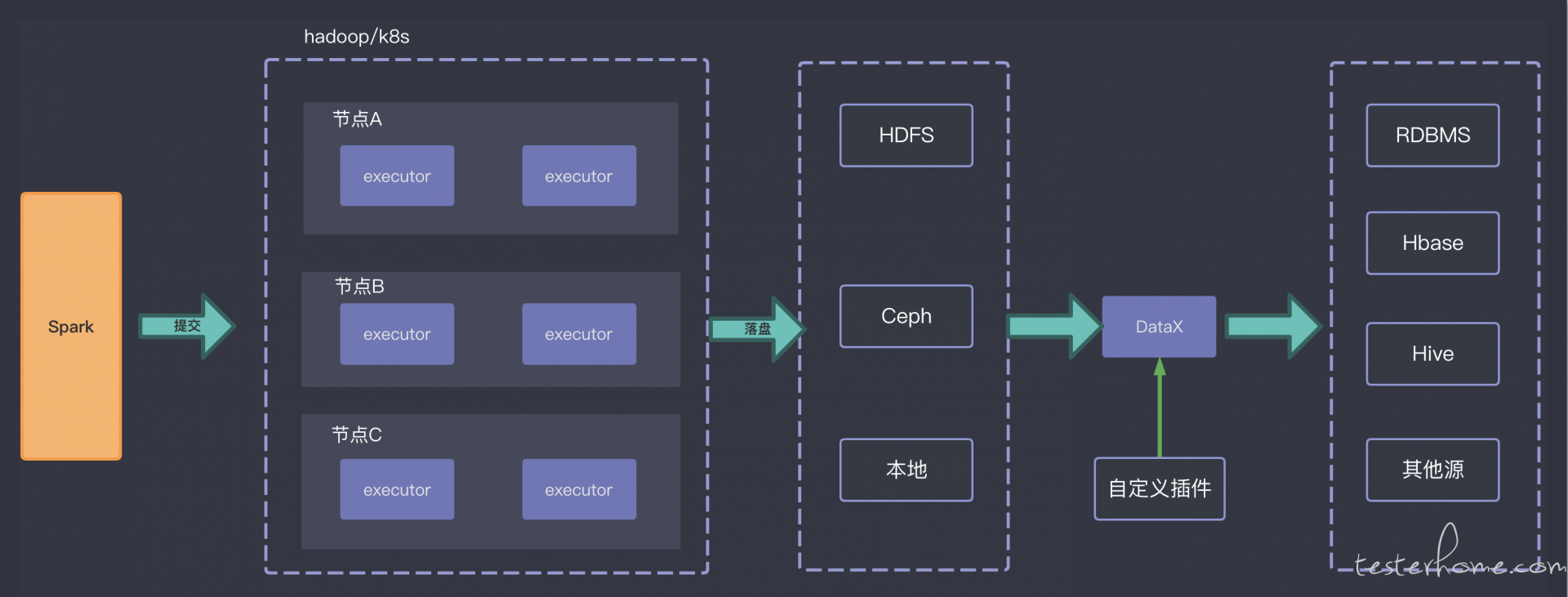
spark 本身就是分布式计算框架, 把造数任务提交到集群上(k8s,hadoop)加速造数进程可提升性能。 这也是用大数据技术测试大数据的一种体现吧。这就解决了上面说的第一个难点。 同样由于 spark 本身就是大数据技术, 所以它在造数的时候很方便的就可以支持保存成各种数据类型和文件格式, 还可以设置落盘时数据分片的数量来测试海量文件分片的场景。 所以第三个难点也就解决了。
而针对第二个难点, 我们自然没有精力为每个数据源都写一个造数工具, 我们采用的是使用 datax 这个开源的数据同步工具, datax 有各种 writer 和 reader 的插件可以在不同的源之间同步数据。 所以我们选择的是先使用 spark 造数落盘, 再把这个数据通过 datax 同步到其他数据源中。
再复杂一点的场景
上面说的其实都是结构化数据, 那我们看看更复杂的场景, 比如我们把数据仓库扩展成数据湖, 数仓的特点是数据都是结构化的, 每个字段都是规定好的。 在导入数仓的时候就做过一轮处理了。 但数据湖的特点是不会对原始数据做处理, 而是直接导入系统中, 这些数据可能是结构化的也半结构化的也可能是非结构化的。 后续会有各种业务需要这些数据。 比如我们已经很熟悉的 AI 平台。 我们的产品对根据不同的数据提供不同的算子(数据处理程序), 有些时候是 ETL 程序, 有些时候是机器学习或者深度学习算法,针对机器学习算法来说做性能测试不仅仅要求数据的量级,也要求数据能抽取特征的维度。 我们可以通过在 spark 程序中控制数据分布来达到精准的控制特征维度的目的。 比如我们再造数的时候给某一列分配 1W 个唯一值, 也就是不管造多少行,都是在这 1w 值里面取的。 那么这一列就是精准的能抽取 1W 维特征出来。所以通过上面的造数工具我们是可以制定规则来满足这些算法的数据需要以测试其性能的。 问题在于非结构化数据, 比如图片,音频和视频。 我们如何能在短时间内造出海量的非结构数据呢? 比如我们之前接到过一个需求, 客户目前已经达到了几十亿张图片的量级。 虽然后面我们讨论过后决定只模式 2 亿级别的数据量,但这也是一个很大的挑战。 我们需要先生成一张图片, 再根据一定算法计算出图片的保存路径和其他元数据, 再把这些元数据保存到数据库中。 在这里面我们能想到的性能瓶颈在于:
IO:不管是生成图片,还是把与数据库交互都会消耗网络和磁盘 io, 2 亿张图片对于 IO 的考验是比较大的
CPU:如果按照传统的思路,为了提升造数性能, 会开很多个线程来并发生成图片,计算元数据和数据交互。 但线程开的太多 CPU 的上下文切换也很损耗性能。 尤其我们使用的是 ssd 磁盘,多线程的模式可能是无法最大化利用磁盘 IO 的。
后面经过讨论, 最后的方案是使用 golang 语言, 用协程 + 异步 IO 来进行造数:
首先 golang 语言的 IO 库都是使用 netpoll 进行优化过的,netpoll 底层用的就是 epoll。 这种异步 IO 技术能保证用更少的线程处理更多的文件。 关于 epoll 为什么性能好可以参考这篇文章:https://www.cnblogs.com/Hijack-you/p/13057792.html 也可以去查一下同步 IO 和异步 IO 的区别。 我大概总结一下就是, 传统的多线程 + 同步 IO 模型是开多个线程抗压力, 每个线程同一时间只处理一个 IO。 一旦 IO 触发开始读写文件线程就会处于阻塞状态, 这个线程就会从 CPU 队列中移除也就是切换线程。 等 IO 操作结束了再把线程放到 CPU 队列里让线程继续执行下面的操作,而异步 IO 是如果一个线程遇到了 IO 操作,它不会进入阻塞状态, 而是继续处理其他的事, 等到那个 IO 操作结束了再通知程序(通过系统中断),调用回调函数处理后面的事情。 这样就保证了异步 IO 的机制下可以用更少的线程处理更多的 IO 操作。 这是为什么异步 IO 性能更好的原因,也是为什么异步 IO 能最大化利用磁盘性能。 比如在这个造图片的场景里, 我在内存中造好图片后,开始写入文件系统, 如果是同步 IO 那这时候就要阻塞了,直到文件写入完毕线程才会继续处理, 但因为我用的异步 IO, 调用玩函数让内存中的数据写入到文件就不管了, 直接开始造下一张图片, 什么时候 IO 结束通知我我在回过头来处理。 所以是可以用更少的线程来完成更多的 IO 操作也就是异步 IO 能很容易的把磁盘性能打满。 我自己测试的时候再自己的笔记本上造 100k 的图片, 大概是 1s 就能造 1W 张图片
其次 golang 的 GMP 模型本身就很高效, 编写异步程序也非常简单。 我也就花了一上午就把脚本写完了。
最后利用 k8s 集群把造数任务调度到集群中, 充分利用分布式计算的优势, 在多台机器上启动多个造数任务共同完成。
原谅我懒了, 上面这个方案的架构图我实在是不想画了, 大家见谅。
结尾
在大数据产品的测试里, 经常会有这种造数的需求。 当然不是所有场景都是要造数测的。 如果大家不是在 TO B 产品中工作并且身处业务层,而不是数据中台层。 那么其实更多的就是直接用线上数据了。
版权声明:本文由[孙高飞]发表于http://testerhome.com/articles/31471
如有侵权,请联系commuinty@eolink.com删除。