数据采集
尽量使用生产数据
上几篇中介绍了模型的评估指标和建模的数据集拆分。 但我在日常的工作中还是碰到了一些坑。 建模是一个很漫长的过程,在给科学家们在建模之前会对原始数据做各种处理。 有时候就可能跟生产数据有些偏差。 所以我们测试模型的时候要尽量使用生产环境中的真实数据。一来数据真实全面,数据场景覆盖率较高。二来也能及早发现一些比较鬼畜的事。 比如我们前两天发现一份几百 M 的数据在 hadoop 上居然有 7800 多个分片,一个分片才几百 k,7800 个 task 在 hadoop 内各种传输,集群直接爆炸的节奏。
呈现时序性的数据
一般使用生产环境的数据会面临一个问题, 如果像是头条,百度这种体量的业务,数据会达到一个很恐怖的量级。一天的数据几十上百个 G 的不夸张。所以要拆分,但是不能盲目的截取一个时间段的数据或者随机采样。 如果我们的业务数据是呈现时序性的,例如推荐系统。我们有一个推荐新闻的业务场景, 这个场景的数据的特点是特征随时间发生巨变。 在某一个时间段里一个关键词是热点,它的权重较高。但可能过了一天以后它的权重就降低了很多。或者说出现了很多新的关键词。模型无法拟合这些新的特征变化, 所以我们才会在这种业务上频繁的加入自学习场景,每日根据最新的数据更新模型。之后我们再详细说明自学习场景的事。 现在我们知道了这种模型无法预测跟它在时间上相差较多的数据。 所以测试的时候首先要了解训练模型的数据处于哪一个时间节点。 然后适当设置一个时间间隔,取这个时间间隔后的数据。
根据某些字段呈现不同分布的数据
除了使用生产数据,根据时序性选取适合的时间段的数据以外,还有一个比较重要的地方是有些数据是随着某一个字段呈现不同的分布态势。 比如我们在脉脉上看到的专栏推荐,会随着用户职业的不同有不同的分布。可能程序员用户最多,财务用户较少。我们在采集测试数据的时候要考虑到我们影响业务的主要字段的分布,均匀的采集数据,例如在这个例子里要设定一个百分比,比如 20%。 我们要在一份数据中根据职位这个字段,分段采集,每个职业取 20% 的数据用来测试。当然在测试模型的时候,除了 AUC,召回,精准等指标的统计,也要在测试的时候对结果进行分组,观察每一类数据在模型下的表现。 例如:
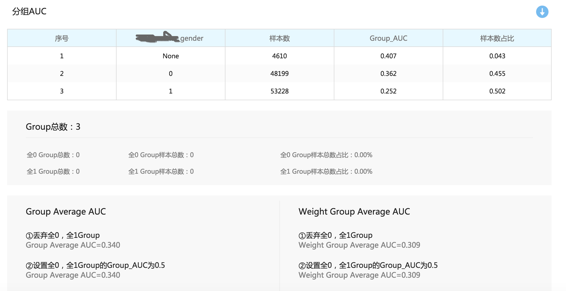
上面是一个模型评估报告中根据性别信息做分组测试的结果。分别是男,女和没有性别信息的数据的测试评分。 我们在测试的时候一般都要针对影响业务的主要字段做这种分组分析,以观察模型是否在所有数据分布下都有良好的表现。 如果某一组的评分很低,就说明模型对这种数据拟合的不好,需要建模工程师针对这种数据对模型进行更新。
自学习场景的测试
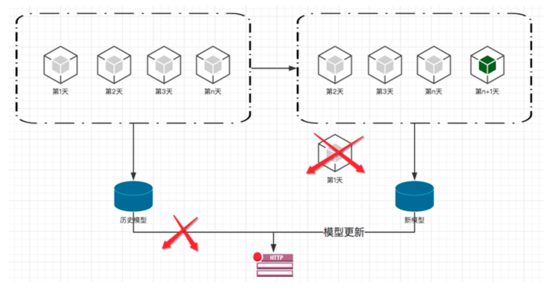
上面说过随着时间的推移数据特征发生巨大的变化,我们需要加入自学习机制。就是利用每天最新的数据来更新模型,以加强模型对新场景的拟合效果。 流程如下图:
数据测试
既然每天都要有新的数据加入到自学习场景中。 所以我们要保证这些数据是没有异常的,使用 spark,Hbase 这些技术,根据业务指定规则,扫描这些数据。一旦有异常就要报警。主要有以下 3 种场景:
版权声明:本文由[孙高飞]发表于https://testerhome.com/wiki/deeplearning
如有侵权,请联系commuinty@eolink.com删除。