1.解压filebeat文件
将filebeat.tar上传到服务器,并解压到指定路径下
—
2.filebeat.yml配置
打开解压完成的filebeat,配置里面的filebeat.yml
###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common
# options. The filebeat.reference.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
# 日志实际路径地址
- /data/learning/learning*.log
fields:
# 日志标签,区别不同日志,下面建立索引会用到
type: "learning"
fields_under_root: true
# 指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的
encoding: utf-8
# 多行日志开始的那一行匹配的pattern
multiline.pattern: ^{
# 是否需要对pattern条件转置使用,不翻转设为true,反转设置为false。 【建议设置为true】
multiline.negate: true
# 匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
multiline.match: after
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
# 日志实际路径地址
- /data/study/study*.log
fields:
type: "study"
fields_under_root: true
# 指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的
encoding: utf-8
# 多行日志开始的那一行匹配的pattern
multiline.pattern: ^\s*\d\d\d\d-\d\d-\d\d
# 是否需要对pattern条件转置使用,不翻转设为true,反转设置为false。 【建议设置为true】
multiline.negate: true
# 匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
multiline.match: after
#============================= Filebeat modules ===============================
#filebeat.config.modules:
# Glob pattern for configuration loading
# path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
#reload.enabled: true
# Period on which files under path should be checked for changes
#reload.period: 10s
#==================== Elasticsearch template setting ==========================
#================================ General =====================================
#============================== Dashboards =====================================
#============================== Kibana =====================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
#kibanaIP地址
host: "localhost:5601"
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
#host: "localhost:5601"
# Kibana Space ID
# ID of the Kibana Space into which the dashboards should be loaded. By default,
# the Default Space will be used.
#space.id:
#============================= Elastic Cloud ==================================
#================================ Outputs =====================================
# Configure what output to use when sending the data collected by the beat.
setup.ilm.enabled: false
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
enabled: true
# Array of hosts to connect to
hosts: ["localhost:9200"]
# index: "logs-%{[beat.version]}-%{+yyyy.MM.dd}"
indices:
#索引名称,一般为 ‘服务名称+ip+ --%{+yyyy.MM.dd}’。
- index: "learning-%{+yyyy.MM.dd}"
when.contains:
#标签,对应日志和索引,和上面对应
type: "learning"
- index: "study-%{+yyyy.MM.dd}"
when.contains:
type: "study"
# Optional protocol and basic auth credentials.
#protocol: "https"
username: "#name"
password: "#pwd"
#----------------------------- Logstash output --------------------------------
#================================ Processors =====================================
# Configure processors to enhance or manipulate events generated by the beat.
processors:
- drop_fields:
# 去除多余字段
fields: ["agent.type","agent.name", "agent.version","log.file.path","log.offset","input.type","ecs.version","host.name","agent.ephemeral_id","agent.hostname","agent.id","_id","_index","_score","_suricata.eve.timestamp","agent.hostname","cloud. availability_zone","host.containerized","host.os.kernel","host.os.name","host.os.version"]
#================================ Logging =====================================
#============================== Xpack Monitoring ===============================
#================================= Migration ==================================
# This allows to enable 6.7 migration aliases
#migration.6_to_7.enabled: true
—
3.启动filebeat
$$
nohup ./filebeat -c filebeat.yml -e >/dev/null 2>&1 & 复制代码
$$
—
4.配置kibana
如果安装启动正常,应可在kibana后台设置看到配置的索引名称。
4.1 配置index pattern
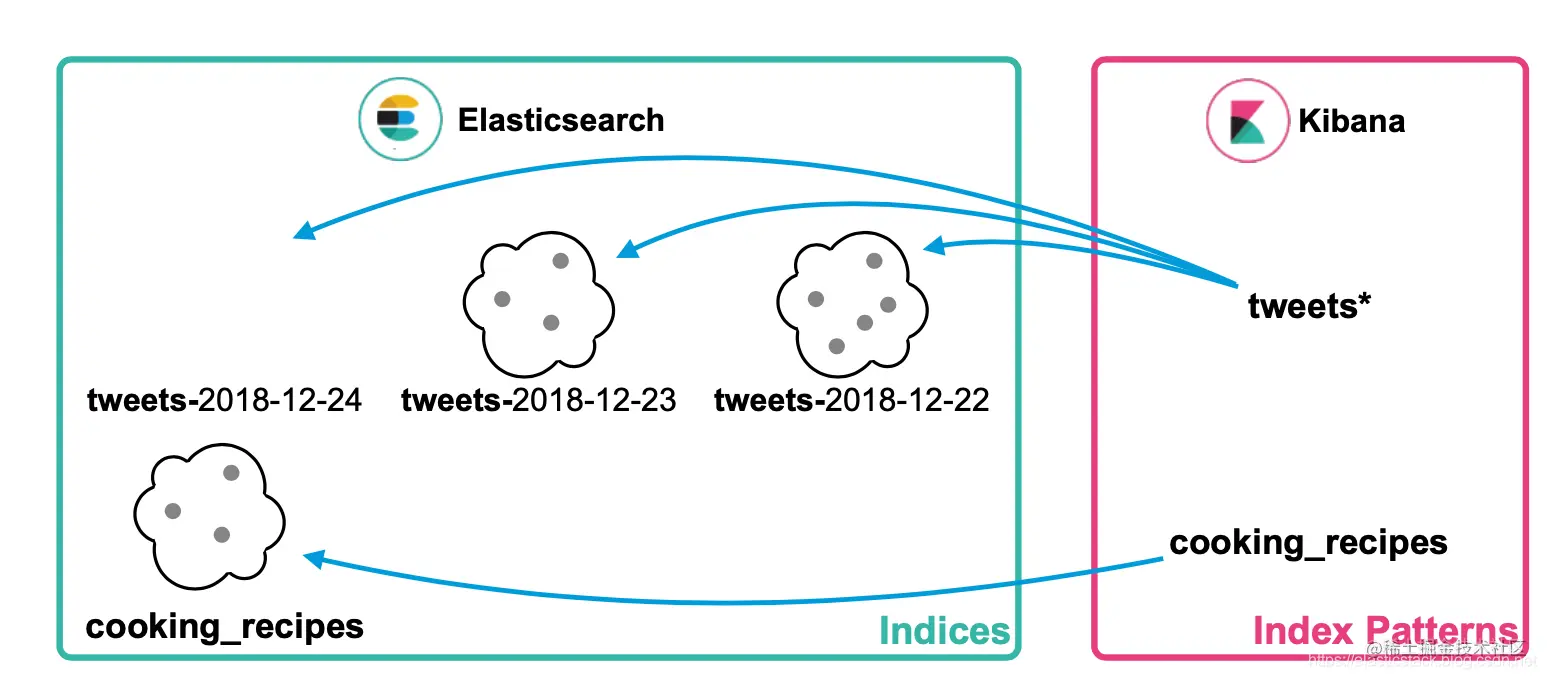
$$
Index pattern:它指向一个或多个 Elasticsearch 的索引,并告诉 Kibana 想对哪些索引进行操作 复制代码
$$
—
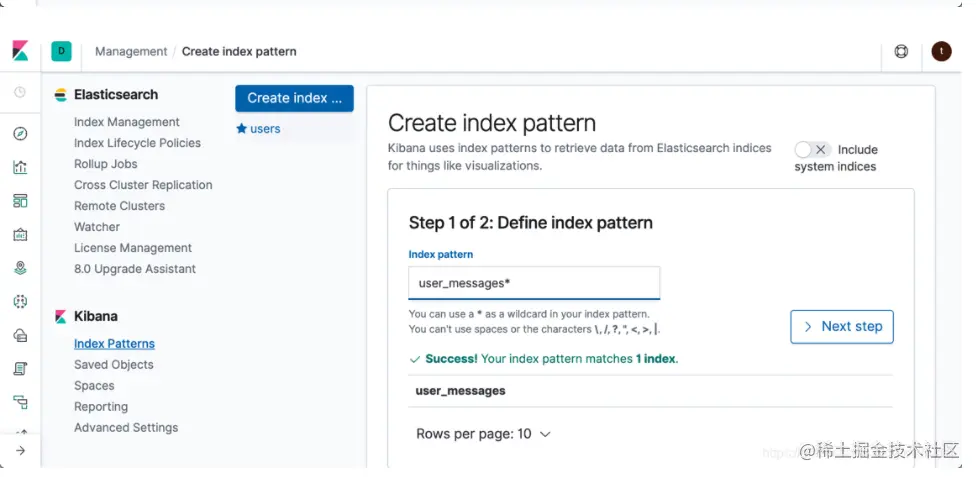 在上面我们需要根据自己的索引的名称输入相应的 index pattern。它可以是指向某单个的索引,也可以通过通配符指向多个索引。
在上面我们需要根据自己的索引的名称输入相应的 index pattern。它可以是指向某单个的索引,也可以通过通配符指向多个索引。 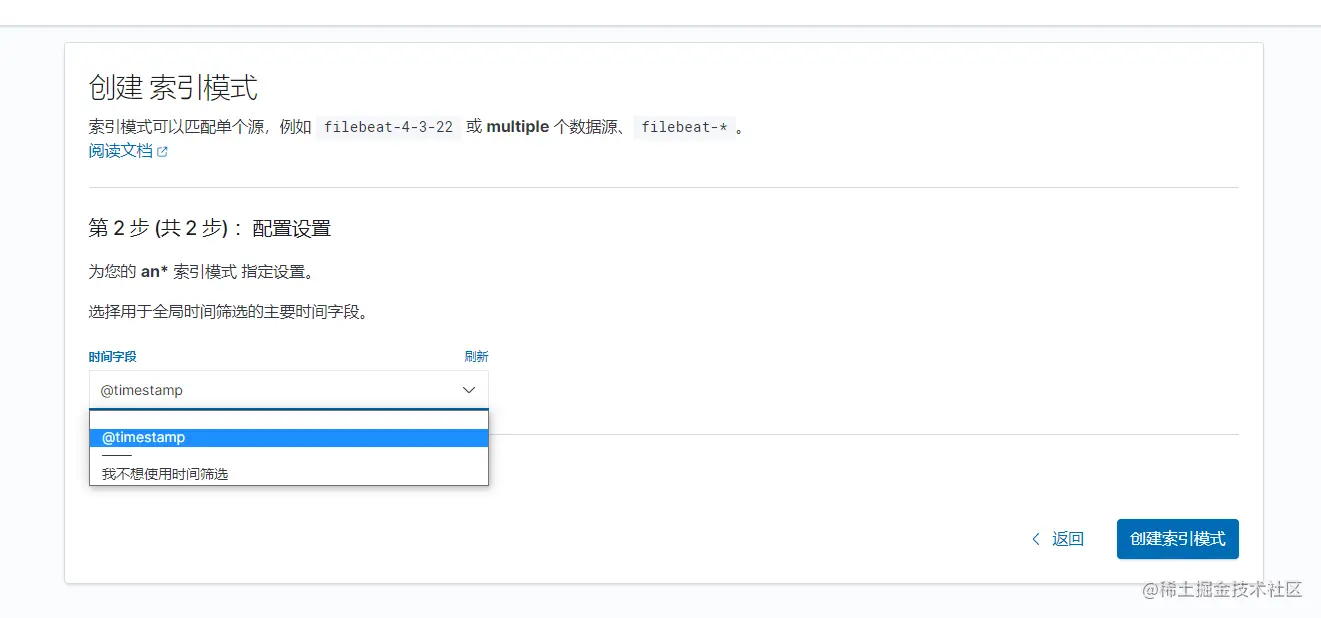
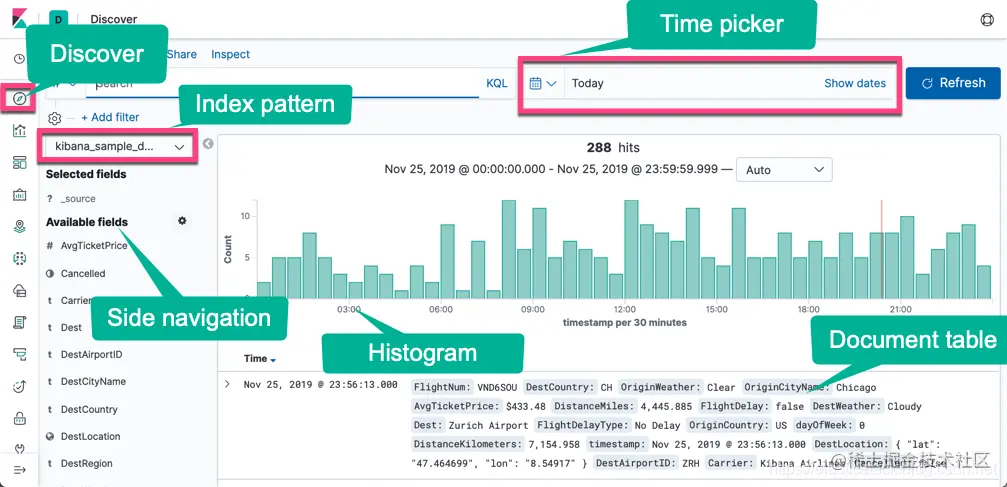
4.2 查看discover
作者:阳光正温暖
链接:https://juejin.cn/post/7003538626453700645
来源:稀土掘金
原文出处及转载信息见文内详细说明,如有侵权,请联系 [commuinty@eolink.com](mailto:commuinty@eolink.com) 删除。