一般情况下,分区数可以配置为Broker节点数的整数倍,比如:Broker节点是3,那么可以设置分区数为3、6、9。但是在broker节点数庞大的情况下,比如大几十、上百、上千则不合适,一般这种也是比较极少的吧,除非有BAT的量级。如果需要可以在选定分区数时可以进一步考虑引入机架等参考因素。
实际情况具体分析,切勿盲目
最后,当你后期增加分区数时,要注意是否有必要或合理。笔者曾见过这种场景:将日志消费后写入es,但是存在消息堆积严重,于是将分区数从6个增加到12个,此时对堆积情况并没有很好得到改善,甚至出现更差(比如同一日志文件日志数据出现不连续,即有序),最后只能删掉主题,重新设置原来的分区数。
因为系统的主要瓶颈在于es的写入能力,造成消费速度慢,从而引起海量日志消息的堆积。所以分析出当前的主要问题(瓶颈等)很重要,切记不能随意或盲目设置分区数。
Broker为节点的意思,我们启动的单个Kafka实例则为一个Broker,多个Broker可以组成Kafka集群
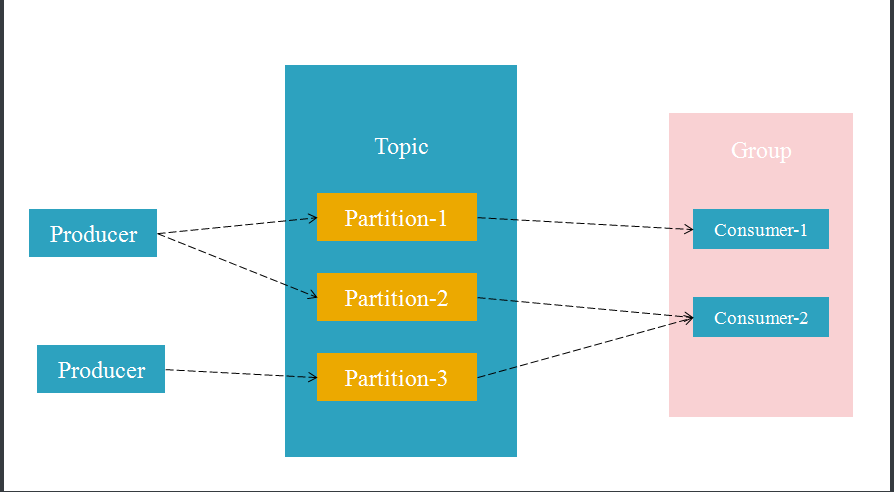
Topic 为主题的意思,也就是相当于消息系统中的队列(queue),一个Topic中存在多个Partition
Partition为分区的意思,是构成Kafka存储结构的最小单位
Partition offset, 为消息偏移量,以Partition为单位,即使在同一个Topic中,不同Partition的offset也是重新开始计算(也就是会重复)
Group 为消费者组的意思,一个Group里面包含多个消费者
Message 为消息的意思,是队列中消息的承载体,也就是通信的基本单位,Producer可以向Topic中发送Message
首先Topic中有分区的概念,每个分区保存各自的数据,而我们的Group这对应着Topic,也就是这个Topic中的数据都是由该Group去消费,也就是允许多个消费者同时消费,这样能大大提高Kafka的吞吐量。不过这样的设计也会带来不少的不便,比如特定场景下你需要去维护多个Partition之间的关系。