简介
与CLH类似,MCS也是由QNode对象构成的链表,每个QNode表示一个锁持有者,表示一个线程要么已经获取锁,要么正在等待锁。它与CLH不同的是,队列是一个显示链表,是通过next指针串起来的。
实现
MCS队列锁的具体实现如下:
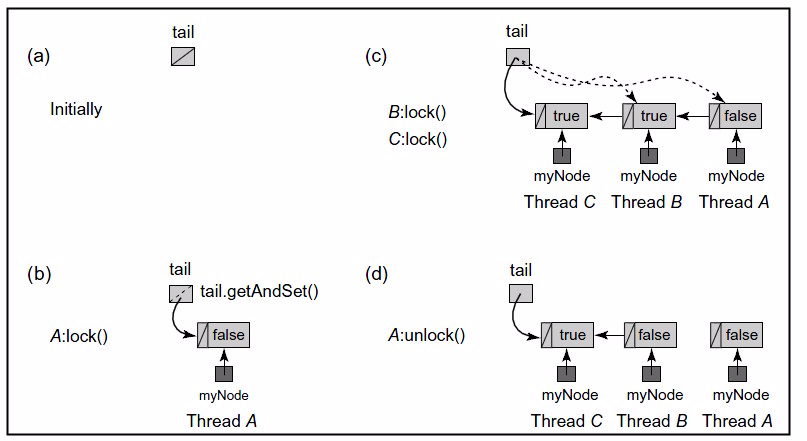
1、如图(a)所示,队列初始化时没有结点,tail=null;
2、如图(b)所示,线程A想要获取锁,于是将自己置于队尾,由于它是第一个结点,它的locked域为false;;
3、如果(c)所示,线程B和C相继加入队列,前面说了这个队列是由next指针串起来的,所以a->next=b,b->next=c。且B和C现在没有获取锁,处于等待状态,所以它们的locked域为true,尾指针指向线程C对应的结点;
4、如果(d)所示,线程A释放锁后,顺着它的next指针找到了线程B,并把B的locked域设置为false。这一动作会触发线程B获取锁。
从上面的实现可以看出,MSC与CLH最大的不同并不是链表是显示还是隐式,而是线程自旋的规则不同,CLH是在前趋结点的locked域上自旋等待,而MSC是在自己的结点的locked域上自旋等待。正因为如此,它解决了CLH在NUMA系统架构中获取locked域状态内存过远的问题。
下面看看MCS队列锁的JAVA实现:
public class MCSLock implements Lock {
AtomicReference<QNode> tail;
ThreadLocal<QNode> myNode;
@Override
public void lock() {
QNode qnode = myNode.get();
QNode pred = tail.getAndSet(qnode);
if (pred != null) {
qnode.locked = true;
pred.next = qnode;
// wait until predecessor gives up the lock
while (qnode.locked) {
}
}
}
@Override
public void unlock() {
QNode qnode = myNode.get();
if (qnode.next == null) {
if (tail.compareAndSet(qnode, null))
return;
// wait until predecessor fills in its next field
while (qnode.next == null) {
}
}
qnode.next.locked = false;
qnode.next = null;
}
class QNode {
boolean locked = false;
QNode next = null;
}
}
lock方法:
若要获得锁,线程会把自己的结点放到队列的尾部,如果队列中开始有结点,就将前一个结点的next结点指向当前结点;
然后就在自己的locked域上自旋等待,直到它的前趋结点把自己的locked设置为false为止。
unlock方法:
若要释放锁,先检查自己的next域是否为null,如果为null,要么当前结点是尾结点,要么还有其他线程正在争用锁。不管是哪种情况都可以采用compareAndSet(q,null)来判断,其中q为当前结点,如果调用成功,则没有其他线程在争用锁,于是将tail设置为null返回;如果调用失败,说明另一个比较慢的线程正在试图获得锁,于是自旋等待它结束。在以上任一种情况,一旦出现有后继结点就将后续结点的locked域设置为false,然后返回。
疑点
对于unlock方法,有人会问既然qnode.next==null,说明qnode是尾结点,那么compareAndSet(q,null)为什么会失败呢?
如下图(a)所示,开始只有线程A在获取锁,A确实是队尾元素,tail指针也指向了它,多线程环境下,一切皆有可能,就在准备进行compareAndSet(q,null)操作时,突然以迅雷不及掩耳之势闯入两个线程B和C,如图(b)所示,这时如果再进行compareAndSet(q,null)操作就会失败。不过在这种情况下,while(qnode.next==null)会跳出循环,紧接着执行下面的两句代码:
qnode.next.locked = false;
qnode.next = null;

可见,释放锁操作在有线程闯入时也是能够正常工作的。
优缺点:
优点是适用于NUMA系统架构,缺点是释放锁也需要自旋等待,且比CLH读、写、CAS等操作调用次数多。
参考资料:
A simple correctness proof of the MCS contention-free lock
Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors
高性能自旋锁 MCS Spinlock 的设计与实现
The Art of Multiprocessor Programming
来源: http://blog.csdn.net/aesop_wubo/article/details/7538934